7. Dataloader Overview
7.7. Section Overview
In this section, we discuss the dataloader objects which retrieve data
within a spatial (and optionally temporal) boundary for the Environmental Mesh.
The dataloaders are responsible for transforming the raw data into a format
that is interpretable by the mesh construction code. This may include reprojecting
to mercator (EPSG:4326) projection, or downsampling to reduce the computing resources
needed to process large datasets. Typically, raw data is stored as a NetCDF or CSV file,
however this can be whatever the user needs, so long as they are cast into either
pandas.DataFrame’s or xarray.Dataset’s for the
Abstract Dataloaders to work with.
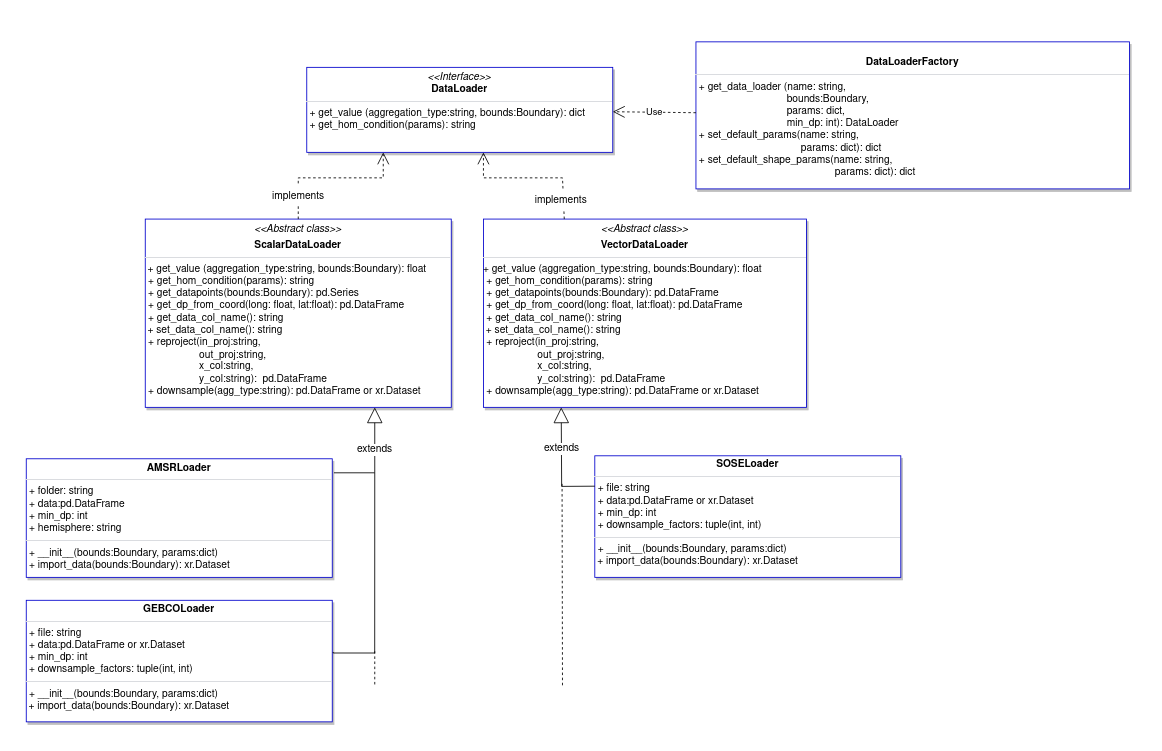
UML Diagram detailing the dataloader subsystem
7.7.1. Dataloader Types
There are three main types of dataloaders that are implemented as abstract classes: Scalar, Vector, and Look-Up Table.
Scalar dataloaders are to be used on scalar datasets; i.e. variables with a single value per latitude/longitude(/time) coordinate. Examples of this are bathymetry, sea ice concentration, etc… While the raw datasets may contain more than one variable (a common example being the existence of values and errors in the same file), these MUST be cut down to just coordinates, and a single variable, in order to work correctly with the abstractScalar dataloader. To read more on how to implement these, follow instructions in Adding Dataloaders page and the abstract scalar dataloader page.
Vector dataloaders are to be used on vector datasets; i.e. variables with multi-dimensional values
per latitude/longitude(/time) coordinate. Examples of this are ocean currents,
wind, etc… The datasets will have multiple data variables, and should be cut down to include only coordinates (‘lat’, ‘long’,
and optionally ‘time’), and the values for each dimensional component of the variable. This will generally be two dimensions,
however the abstractVector dataloader should be flexible to n-dimensional data.
Rigor should be taken when testing these dataloaders to ensure that the outputs of get_value() method of these dataloaders produces outputs that make sense.
To read more on how to implement these, follow instructions in Adding Dataloaders page and abstract vector dataloader page.
Look-up Table Dataloaders are to be used on datasets where boundaries define a value. Real data is always preferred to this method, however in the case where there is no data, the LUT can provide an alternative. Examples of this include ice density, exclusion zones, and marine-protected areas. For these examples, weather conditions dictate their values, and these weather conditions can be localised to specific areas. To read more on how to implement these, follow instructions in Adding Dataloaders page and abstract LUT dataloader page.
7.7.2. Abstract Dataloaders
To look at specific abstract dataloaders, use the following links:
These are the templates to be used when implementing new dataloaders into MeshiPhi.
They have been split into three separate categories: Scalar, Vector, and LUT, detailed in Dataloader Types.
The abstract classes generalise the methods used by each dataloader type to produce outputs
that the Environmental Mesh can retrieve via the dataloader interface.
Scalar and Vector dataloaders are flexible in that they can store and process data as both xarray.Dataset’s or
pandas.DataFrame’s (and by extension, dask.DataFrames’s).
When creating your own, dask and xarray should be utilised as much as possible to
reduce memory consumption.
LUT dataloaders are flexible in that they can read in CSV’s, GeoJSON’s, or Shapefiles, but are otherwise stored internally
as GeoPandas dataframes.
The abstract base classes define the __init__() function to have the following process:
Read in params from config
Add params from
self.add_default_params(), defined by user when creating a dataloaderDownsample data if required and if loaded as
xarray.DatasetReproject data if required
Trim datapoints to initial boundary
Rename data column name if defined in params