5.1. Configuration - Mesh Construction
Below is a full configuration file for building an environmental mesh using synthetic data generated from Gaussian
Random Fields (GRFs). This configuration file generates the fields ‘SIC’, ‘elevation’, ‘thickness’, ‘density’, ‘uC, vC’
(currents) and ‘u10, v10’ (winds). The full configuration file is available in the file location
examples/environment_config/grf_example.config.json on GitHub. Other example configuration files are also
available at this location, including configuration files which build meshes using real datasets.
{
"region": {
"lat_min": 0,
"lat_max": 10,
"long_min": 0,
"long_max": 10,
"start_time": "2017-02-01",
"end_time": "2017-02-04",
"cell_width": 10,
"cell_height": 10
},
"data_sources": [
{
"loader": "scalar_grf",
"params": {
"data_name": "SIC",
"min": 0,
"max": 100,
"seed": 16,
"offset": 5,
"splitting_conditions": [
{
"SIC": {
"threshold": 75,
"upper_bound": 1.0,
"lower_bound": 0.0
}
}
],
"dataloader_name": "scalar_grf",
"downsample_factors": [
1,
1
],
"aggregate_type": "MEAN",
"min_dp": 5,
"in_proj": "EPSG:4326",
"out_proj": "EPSG:4326",
"x_col": "lat",
"y_col": "long",
"size": 512,
"alpha": 3,
"binary": false,
"threshold": [
0,
1
],
"multiplier": 1
}
},
{
"loader": "scalar_grf",
"params": {
"data_name": "elevation",
"min": -100,
"max": 50,
"seed": 30,
"splitting_conditions": [
{
"elevation": {
"threshold": -10,
"upper_bound": 1.0,
"lower_bound": 0.0
}
}
],
"dataloader_name": "scalar_grf",
"downsample_factors": [
1,
1
],
"aggregate_type": "MEAN",
"min_dp": 5,
"in_proj": "EPSG:4326",
"out_proj": "EPSG:4326",
"x_col": "lat",
"y_col": "long",
"size": 512,
"alpha": 3,
"binary": false,
"threshold": [
0,
1
],
"multiplier": 1,
"offset": 0
}
},
{
"loader": "scalar_grf",
"params": {
"data_name": "thickness",
"min": 0.65,
"max": 1.4,
"seed": 44,
"dataloader_name": "scalar_grf",
"downsample_factors": [
1,
1
],
"aggregate_type": "MEAN",
"min_dp": 5,
"in_proj": "EPSG:4326",
"out_proj": "EPSG:4326",
"x_col": "lat",
"y_col": "long",
"size": 512,
"alpha": 3,
"binary": false,
"threshold": [
0,
1
],
"multiplier": 1,
"offset": 0
}
},
{
"loader": "scalar_grf",
"params": {
"data_name": "density",
"min": 850,
"max": 1000,
"seed": 40,
"dataloader_name": "scalar_grf",
"downsample_factors": [
1,
1
],
"aggregate_type": "MEAN",
"min_dp": 5,
"in_proj": "EPSG:4326",
"out_proj": "EPSG:4326",
"x_col": "lat",
"y_col": "long",
"size": 512,
"alpha": 3,
"binary": false,
"threshold": [
0,
1
],
"multiplier": 1,
"offset": 0
}
},
{
"loader": "vector_grf",
"params": {
"data_name": "uC,vC",
"min": 0,
"max": 1,
"seed": 21,
"dataloader_name": "vector_grf",
"downsample_factors": [
1,
1
],
"aggregate_type": "MEAN",
"min_dp": 5,
"in_proj": "EPSG:4326",
"out_proj": "EPSG:4326",
"x_col": "lat",
"y_col": "long",
"size": 512,
"alpha": 3,
"vec_x": "uC",
"vec_y": "vC"
}
},
{
"loader": "vector_grf",
"params": {
"data_name": "u10,v10",
"min": 0,
"max": 1,
"seed": 21,
"dataloader_name": "vector_grf",
"downsample_factors": [
1,
1
],
"aggregate_type": "MEAN",
"min_dp": 5,
"in_proj": "EPSG:4326",
"out_proj": "EPSG:4326",
"x_col": "lat",
"y_col": "long",
"size": 512,
"alpha": 3,
"vec_x": "uC",
"vec_y": "vC"
}
}
],
"splitting": {
"split_depth": 6,
"minimum_datapoints": 5
}
}
The configuration file used for mesh construction contains information required to build a discretised model of the environment. Information here dictates the region in which the mesh is constructed, the data contained within the mesh and how the mesh is split to a non-uniform resolution. The configuration file used to generate a mesh is stored in the output mesh json in a section titled ‘mesh_info’.
The mesh configuration file contains three primary sections:
5.1.1. Region
The region section gives detailed information for the construction of the Discrete Mesh. The main definitions are the
bounding region and temporal portion of interest (long_min, lat_min, long_max, lat_max, start_time, end_time), but
also the starting shape of the spatial grid cell boxes (cell_width, cell_height) is defined before splitting is
applied. Further detail on each parameter is given below:
"region": {
"lat_min": 0,
"lat_max": 10,
"long_min": 0,
"long_max": 10,
"start_time": "2017-02-01",
"end_time": "2017-02-04",
"cell_width": 10,
"cell_height": 10
}
where the variables are as follows:
long_min (float, degrees) : Minimum Longitude Edge of the Mesh
long_max (float, degrees) : Maximum Longitude Edge of the Mesh
lat_min (float, degrees) : Minimum Latitude Edge of the Mesh
lat_max (float, degrees) : Maximum Latitude Edge of the Mesh
start_time (string, ‘YYYY-mm-dd’) : Start Datetime of Time averaging
end_time (string, ‘YYYY-mm-dd’) : End Datetime of Time averaging
cell_width (float, degrees) : Initial Cell Box Width prior to splitting
cell_height (float, degrees) : Initial Cell Box Height prior to splitting
Note
Variables start_time and end_time also support reference to system time using the keyword TODAY e.g.
“startTime”: “TODAY” , “endTime”: “TODAY + 5”
“startTime”: “TODAY - 3”, “endTime”: “TODAY”
5.1.2. Data Sources
The ‘data_sources’ section of the configuration file defines which information will be added to the mesh when constructed. Each item in the list of data sources represents a single dataset to be added to the mesh.
"data_sources": [
{
"loader": "scalar_grf",
"params": {
"data_name": "SIC",
"min": 0,
"max": 100,
"seed": 16,
"offset": 5,
"splitting_conditions": [
{
"SIC": {
"threshold": 75,
"upper_bound": 1.0,
"lower_bound": 0.0
}
}
],
"dataloader_name": "scalar_grf",
"downsample_factors": [
1,
1
],
"aggregate_type": "MEAN",
"min_dp": 5,
"in_proj": "EPSG:4326",
"out_proj": "EPSG:4326",
"x_col": "lat",
"y_col": "long",
"size": 512,
"alpha": 3,
"binary": false,
"threshold": [
0,
1
],
"multiplier": 1
}
},
... other data_sources
]
where the variables are as follows:
- loader (string)The name of the data loader to be used to add this data source to the mesh
see the abstractScalarDataloader doc page for further information about the available data loaders.
params (dict) : A dictionary containing optional parameters which may be required by the specified data loader in ‘loader’. These parameters include the following:
value_fill_types (string) : Determines the actions taken if a cellbox is generated with no data. The possible values are either parent (which implies assigning the value of the parent cellbox), zero or nan.
aggregate_type (string) : Specifies how the data within a cellbox will be aggregated. By default aggregation takes place by calculating the mean of all data points within the CellBoxes bounds. aggregate_type allows this default to be changed to other aggregate function (e.g. MIN, MAX, COUNT).
- [scalar] splitting_conditions (list)The conditions which determine if a cellbox should be split based on a scalar dataset.
threshold (float) : The threshold above or below which CellBoxes will be sub-divided to separate the datapoints into homogeneous cells.
upperBound (float) : A percentage normalised between 0 and 1. A CellBox is deemed homogeneous if greater than this percentage of data points are above the given threshold.
lowerBound (float) : A percentage normalised between 0 and 1. A Cellbox is deemed homogeneous if less than this percentage of data points are below the given threshold.
- [vector] splitting_conditions (list)The conditions which determine if a cellbox should be split based on a vector dataset.
curl (float) : The threshold value above which a cellbox will split. Is calculated as the maximum value of Curl(F) within a cellbox (where F is the vector field).
Note
Splitting conditions are applied in the order they are specified in the configuration file.
5.1.3. Splitting
Non-uniform mesh refinement is done by selectively sub-dividing cells. Cell sub-division is performed whenever a cell (of any size) is determined to be inhomogeneous with respect to a specific characteristic of interest such as SIC or ocean depth (this characteristic is defined as a splitting condition inside the data source’s params as illustrated above).
In the figure below, a graphical representation of the splitting decision making process is shown. In this, the blue histogram represents an arbitrary dataset, the orange histogram represents the values in the dataset that are greater than the threshold (and denoted ‘A’ in the formulae), the black line is the threshold value, ‘UB’ is the upper bound, and ‘LB’ is the lower bound. To be specific, this is a probability distribution, and hence the area under the orange curve ‘A’ is a decimal fraction of the total dataset (which would have an area of 1).
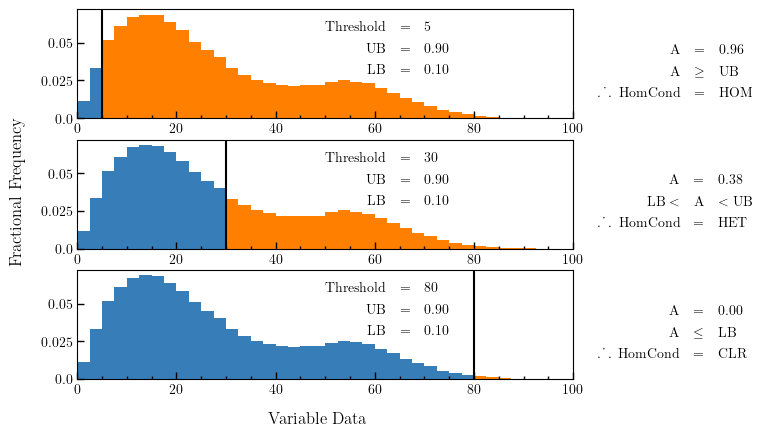
Plot showing how cellbox homogeneity is decided
If the orange area
A <= LB, then the homogeneity condition isCLR.If the orange area
A >= LB, then the homogeneity condition isHOM.If the orange area
LB < A < UB, then the homogeneity condition isHET.
CLR, HOM, and HET are used to determine if a cellbox
should be split or not. There is also a fourth homogeneity condition MIN
which is only triggered when the number of datapoints within the cellbox is lower
than the minimum_datapoints specified in the config. The values are checked in this order:
MIN- Do not split the cellboxCLR- Do not split the cellbox, but allow splitting if other datasets returnHETHOM- Do not split the cellboxHET- Split the cellbox
In the extreme case where UB = 1 and LB = 0, the cellbox will
always split if there are any datapoints above or below the UB/LB respectively.
Imagining a plot similar to the figure above,
If the histogram is entirely blue,
return 'CLR'If the histogram is entirely orange,
return 'HOM'If there’s both colours,
return 'HET'
The splitting section of the Configuration file defines the splitting parameters that are common across all the data sources and determines how the CellBoxes that form the Mesh will be sub-divided based on the homogeneity of the data points contained within to form a mesh of non-uniform spatial resolution.
"splitting": {
"split_depth":6,
"minimum_datapoints":5
}
where the variables are as follows:
split_depth (float) : The number of times the MeshBuilder will sub-divide each initial cellbox (subject to satisfying the splitting conditions of each data source)
minimum_datapoints (float) : The minimum number of datapoints a cellbox must contain for each value type to be able to split